

 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Biological science
ISSN 2500-3399
ПИ №ФС77-57454
ALLOCATION OF INFORMATIVE CHARACTERISTICS OF A BIOLOGICAL OBJECT FROM THE REGISTERED SIGNAL

Актуальной проблемой проектирования систем поддержки принятия классификационных решений соотнесения состояния биологического объекта к определенной страте (классу) является задача выделения маломощного сигнала на фоне большой зашумленности и характеристик с приемлемым уровнем адекватности значений диагностирующих состояние. Это касается и сложности выделения маломощных сигналов из шумов и формирования информативных множеств, достоверно характеризующих биообъект. С целью повышения эффективности диагностики заболеваний на ранних стадиях и улучшения качества медицинского обслуживания населения в целом.
Одним из наиболее распространенным подходом к построению классификационных систем является распознавание образов, начальным этапом которого является формирование множества информативных характеристик, характеризующих альтернативные классы. В дальнейшем, при построении систем дифференциальной диагностики (например, в медицине [18, 20]), что характерно для иерархических деревьев принятия решений, достаточно на каждом этапе бинарного дерева осуществить соотнесение объекта к одному из альтернативных классов w0 и w1.
Для выбора множества характеристик, обладающих необходимой степенью классификационных возможностей, предлагается следующая методика. Пусть задано некоторое исходное множество характеристик {Pr} g , где g – исходное количество, g?0. Требуется сформировать множество характеристик {Prо}gо , 1≤go≤g, обладающее наибольшими классификационными возможностями. Из разницы между множествами {Pr}g и {Prоэ}gоэ возникает задача отбора характеристик, обладающих наибольшими классификационными возможностями, апробированными, статистически доказуемыми, формализованными методами.
Для этого необходимо иметь по каждому из альтернативных классов некоторые множества численных данных. Речь идет, в данном случае, о разведочном анализе и априорной принадлежности к нормальному закону распределения (в этом случае приемлемые результаты могут быть получены на выборках малого объема).
Наряду с регистрируемыми характеристиками (множеством {Х}) для повышения качества классификации предлагается формировать дополнительное множество интегральных (множество {Y}), расчет элементов которого проводится по формуле (1).
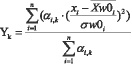 (1),
(1),
Yk - интегральная характеристика, k - индекс интегральной характеристики, 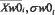 - соответственно, модальное значение (в случае нормального распределения совпадает с математическим ожиданием и средним значениями) и средне-квадратичное отклонение (СКО) , полученное на обучающей выборке для некоторого класса «базовый»,
- соответственно, модальное значение (в случае нормального распределения совпадает с математическим ожиданием и средним значениями) и средне-квадратичное отклонение (СКО) , полученное на обучающей выборке для некоторого класса «базовый», 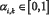 - весовые коэффициенты, определяющие информационный вклад характеристики xi в формирование интегральной Yk.
- весовые коэффициенты, определяющие информационный вклад характеристики xi в формирование интегральной Yk.
Весовые коэффициенты в указанной формуле предлагается определять следующими способами:
1. Путем назначения экспертами, исходя из личного опыта и анализа информационных источников.
2. Автоматически – на основе применения определенного статистически обоснованного математического аппарата.
3. Смешанным способом.
Во всех трех способах необходимо иметь единые шкалы измерений и ограничений. Принимаем ограничения:
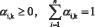 (2),
(2),
где n – количество частных показателей множества {Х}, k – номер интегральной характеристики Y (k≥0).
Предлагается следующая методика определения рассматриваемых весовых коэффициентов αi,k информативности (действительна только при наличии двух альтернативных классов):
1. Регистрируются для каждого альтернативного класса значения элементов множеств 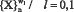 (где n – количество характеристик).
(где n – количество характеристик).
2. По значениям коэффициента Стьюдента на заданном уровне значимости (ошибки первого рода) осуществляется селекция с предположительно незначительными классификационными возможностями. В результате селекции для дальнейшего формирования информативного признакового пространства используется множество 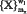 , где mx – количество характеристик, оставшихся после селекции.
, где mx – количество характеристик, оставшихся после селекции.
3. По каждому показателю (признаку) вычисляются коэффициенты Стьюдента различий между двумя альтернативными классами – формируется множество 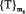 , элементами которого (
, элементами которого (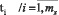 ) являются значения коэффициентов Стьюдента.
) являются значения коэффициентов Стьюдента.
4. Элементы полученного множества ранжируются (по убыванию или возрастанию). Строится диаграмма значений полученного ряда, по которой исследователь определяет необходимое количество (my ,my≤mx) и «состав» интегральных характерестик путем выделения кластеров близких (по некоторой мере исследователя) значений ранжированных коэффициентов Стьюдента.
5. Каждому кластеру k (k=1,…,my) ставится в соответствие определенная интегральная характеристика Yk и соответствующее подмножество . Формула (2) модифицируется в формулу:
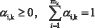 (3).
(3).
6. Для каждой интегральной характеристики Yk с учетом вычисленных в п.2 значений коэффициентов Стьюдента и выделенных в п.3 кластеров определяются значения соответствующих весовых коэффициентов в (3) по формуле:
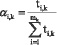 (4).
(4).
Полученные величины весовых коэффициентов позволяют в дальнейшем формировать значения множества {Y}.
Таким образом, множество информативных характеристик {Pr}g для решения задачи обучения системы классификации (диагностики) формируется по формуле:
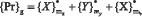 (5),
(5),
где 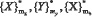 - соответственно: множество отобранных характеристик по изложенной выше методике, множество отобранных интегральных характеристик, множество отобранных экспертом характеристик, - элементами всех множеств являются «идентификаторы».
- соответственно: множество отобранных характеристик по изложенной выше методике, множество отобранных интегральных характеристик, множество отобранных экспертом характеристик, - элементами всех множеств являются «идентификаторы».
Для формирования информативного множества и принятия решении о включении в него признака так же рекомендуется использовать методологию принятия решений Саати Т.Л. [13]
Формируется матрица предпочтительности W, элементы которой для показателей i и j различаются по 9 степеням (признак i предпочтительнее j): wi,j=1 - равная степень предпочтительности, wi,j=2 - слабая wi,j=3 - средняя, wi,j=4 - предпочтение выше среднего, wi,j=5 - умеренно сильное, wi,j=6 - сильное, wi,j=7 - очень сильное (очевидное), wi,j=8 - очень, очень сильное (абсолютное), wi,j=9 – абсолютное.
Анализ матрицы позволяет после преобразования группировать признаки по кластерам предпочтительности с помощью предлагаемого IJ-преобразования. Строки I меняются местами со строками J до тех пор, пока сумма произведений значений элемента матрицы W* на расстояние этого элемента до главной диагонали не станет минимальной (формула (6)). Таким образом, вокруг главной диагонали модифицированной матрицы предпочтений W* сгруппируются элементы с максимальными значениями.
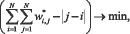 (6)
(6)
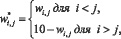
где N– количество анализируемых признаков до селекции.
Упорядочивание признаков по убыванию рангов информативности позволит определить степень предпочтения.
Целесообразно полагать, что для минимизации ошибки и принятия ложных решений из уже сформированного множества следует выделить ряд наиболее информативных характеристик, которые бы наиболее достоверно охарактеризовали исследуемый биологический объект.
Например, информативность отдельной характеристики из множества {Х} в работах [6, 7, 19] предлагается определять следующими методами [15].
Первый метод основан на нелинейной дискриминантной функции, определённой для классов (подразумевается бинарное иерархическое дерево решений). Он подразумевает:
– задание функции отклика для каждого класса w0 и w1;
– структурно-параметрическую идентификацию полинома Габора, с помощью алгоритма МГУА [6, 11];
– вычисление мультипликанта для каждого аргумента;
– определение аддиативно-мультипликативного влияния показателя xi на функцию отклика;
– введение «относительной погрешности отличий» (ОПО) (рекомендуется 0,01≤ε<0,1) и пересчёт значений величины мультипликативного влияния с учётом ОПО;
– упорядочивание xi по мере убывания в диапазоне, заданным ОПО;
– формирование кортежей признаков для классов: 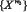 и
и 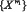 ;
;
– формирование множества рангов 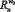 и
и 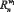 по кортежам;
по кортежам;
– формирование итогового множества информативных признаков;
– вычисление информативности признака Inf(xj) по формуле:
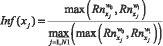 (7)
(7)
где 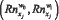 – значение ранга показателя xi в w0 и w1, соответственно.
– значение ранга показателя xi в w0 и w1, соответственно.
Во втором методе формирование множества информативных характеристик и вычисление значения Inf(xj), основывается на предварительной идентификации аппроксимирующего полинома Габора для каждой характеристики из начального множества {X}. В этом случае, процедура идентификации повторяется N раз для каждого класса w0 и w1, последовательно формируя множества {Z}={Х}–xj и отклики Y(Z)=xj.
В результате формируются множества аппроксимантов для каждого класса. Аппроксиманты, значения коэффициента детерминации которых меньше определенного порогового значения, не учитываются. Минимальный объем множества аппроксимантов устанавливается исследователем - рекомендуется не менее 3.
Для каждого альтернативного класса формируются матрицы значений 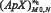 , по которым строятся векторы значений
, по которым строятся векторы значений 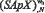 и
и 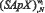 .
.
Кортежи показателей и формируются для каждого класса по мере убывания xi по вектору значений с учётом ОПО.
Далее вычисление информативности осуществляется аналогично действиям, рассмотренным в способе 1.
В третьем методе переменные принимают значения «true» («1») либо «false» (0). С определенной точностью для возможности применения подходов, изложенных в способе 1 и 2, используют аналог полинома Габора Yв*(Zв*) для логических функций в виде формулы (8), на основании аналогов арифметических операций логическим функциям [10].
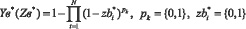 ,(8)
,(8)
Далее расчеты аналогичны 1 и 2 методам.
В четвёртом методе осуществляется упорядочивание характеристик с последующим вычислением рангов, включением в информативный кортеж и вычислением информативности аналогично ранее рассмотренными способами на основании гипер- объемов H. При этом проводятся процедуры разведочной кластеризации с вычислением величины изменения качества кластеризации dHxj при исключении из рассмотрения анализируемой характеристики [12].
dHxj может принимать как положительные, так и отрицательные значения. В последнем случае после селекции наблюдается ухудшение качества классификации согласно общему гипер-объему пространства анализируемых показателей H.
Описанные методы применимы при априорно известном множестве характеристик. Однако на практике, например при исследовании биообъекта [2], часто необходимо определять информативность характеристики в текущий момент времени.
В случае, если биологический объект характеризуется некоторым сигналом небольшим объемом в работе [14] предлагается применить следующий подход.
В анализе сигнала используется фильтр, основанный на различии фаз измеряемого сигнала (регулярная функция) и шума (случайная функция, причём математическое ожидание шума принимается равным нулю).
Опорный импульс, применяемый в фильтре, имеет две прямоугольные ступени с различными амплитудами, общая длительность ступеней значительно меньше интервала наблюдения Тн.
При проведении измерений фрагмент искомого сигнала помещается на вторую ступень опорного импульса. В качестве измеряемой характеристики вычисляется фаза основной гармоники e–jwt при w=1. Для оценки величины сигнала используется разность фаз опорного импульса с сигналом и без него.
При значениях D и M (M=TH/TИ, а D=U2/ U1), близких к единице, увеличивается чувствительность фазы к изменению напряжения (амплитуды ступени).
При этом зависимость фазы от D и М имеет вид [1, 15]:
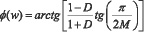 (9)
(9)
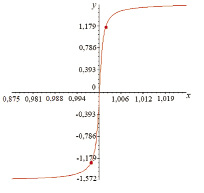
Рис. 1. Зависимость значения фазы основной гармоники опорного сигнала от отношения амплитуд первой и второй ступеней
Для повышения информативности результатов следует обеспечивать попадание фазы опорного импульса и фазы импульса с изменённым фрагментом сигнала на квазилинейный участок графика зависимости от параметра φ(D) (точки на кривой рис. 1). Для этого первую ступень опорного импульса следует принять равной 1, затем вычислить значение D (начальная фазы основной гармоники (w=1) попадёт на нижний конец квазилинейного участка кривой φ(D)).
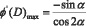 (10)
(10)
После формирования данным образом опорного импульса вычисляется среднее значение измеряемого фрагмента сигнала, которое может быть оценено через разность фаз основной гармоники опорного импульса с сигналом и без него [1].
Затем этот фрагмент умножается на коэффициент:
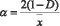 , (11)
, (11)
где x - среднее значение фрагмента «сигнал + шум».
Восстановление сложных сигналов проводят путём оценки средних значений отдельных их фрагментов. Для этого исходный сигнал формируется в виде импульса с колоколовидной огибающей, к нему добавляется шум в виде последовательности случайных нормально распределённых чисел. Зашумлённый сигнал разбивается на фрагменты, для каждого такого фрагмента описанным выше способом оценивается среднее значение сигнала [15].
В результате из некогерентного шума формируется информативный сигнал, по которому можно вести дальнейший анализ [9].
Для вычисления значения информативных параметров снятого сигнала [5,17], предлагается использовать функциональные параметры, характеризующие поведение системы, способной принимать решение в текущий момент времени в соответствии с учетом прошлого опыта и прогнозирования будущего [3, 4].
Целесообразное полагать, что биологическая система должна принимать решения в момент времени t, при регистрации значения информативного сигнала y(t). Так как автономная система управления организмом систематически учитывает лучший результат «прошлого» опыта и автоматически прогнозирует развитие ситуации в будущем, то сигнал y(t) может быть представлен в виде [8]:
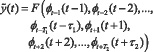 , (12)
, (12)
где: φt±i(t±i) – частный аргумент-функционал, отражающий состояние анализируемой системы в моменты времени (t±i); τ1 и τ2 – максимальное время упреждения и экстраполяции (прогноза), соответственно; T1 и T2 формирующий индекс частных аргумент-функционалов, F() интегральный «опытно-прогностический функционал» – FPF(t)).
В первом приближении частные спектральные аргумент-функционалы представляются линейными преобразованиями:
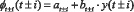 . (13)
. (13)
Множество значений информативных хронометрических параметров в момент времени t+1, формируется «Модулем «фантазий», который содержит правила идентификации 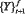 по
по 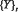 и рассогласования между прогнозируемым состоянием St+1 и реально регистрируемым
и рассогласования между прогнозируемым состоянием St+1 и реально регистрируемым 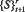 . Обучение заканчивается, когда указанное рассогласование достигнет приемлемого порога величины [8] (задается в общем случае нижней и верхними границами).
. Обучение заканчивается, когда указанное рассогласование достигнет приемлемого порога величины [8] (задается в общем случае нижней и верхними границами).
Выводы
Рассмотренные подходы позволяют формализовать выделение множеств информативных прямых и латентных характеристик биологического объекта путём анализа сигналов различных уровней мощности на основе применения как упреждающих, так и прогнозируемых значений сигнала. Анализ осуществляется с помощью применения самоорганизационной концепции моделирования, дифференцированного анализа и метода анализа иерархий. Исследования в этом направлении представляются новыми и перспективными для решения задачи диагностики состояния анализируемого биообъекта.
Библиографическая ссылка
Артеменко М.В., Сотникова А.Д. ВЫДЕЛЕНИЕ ИНФОРМАТИВНЫХ ХАРАКТЕРИСТИК БИОЛОГИЧЕСКОГО ОБЪЕКТА ИЗ РЕГИСТРИРУЕМОГО СИГНАЛА // Научное обозрение. Биологические науки. 2017. № 1. С. 31-35;URL: https://science-biology.ru/en/article/view?id=1032 (дата обращения: 24.07.2026).