

 science-review.ru
science-review.ru
Профилактика, превентивная диагностика и лечение онкологических заболеваний желудка представляют актуальную проблему во всем мире. По сводным эпидемиологическим данным, это заболевание в мире является четвертым наиболее частым после рака легкого, молочной железы, толстой кишки. Ежегодно диагностируется более 930 тысяч новых случаев выявления заболевания, одногодичная летальность составляет более 700 тыс. (более 75%) [27]. В Российской федерации ежегодно онкология желудка фиксируется у 46 тысяч человек, а одногодичная летальность составляет 56% [28]. Среднее время от появления специфических симптомов до постановки диагноза «рак желудка» (РЖ) составляет 3 месяца, что свидетельствует как о поздней обращаемости пациентов к врачу, и об объективных сложностях диагностики и о необходимости оптимизации тактики обследования на превентивном или поликлиническом уровнях.
В настоящее время мероприятия в области превентивной медицины [26] и профилактика рака желудка [28] сводится к опросу потенциальных больных, принадлежащих к группе риска во время плановой диспансеризации, скрининга с использованием и без средств телемедицины [13] путем сбора жалоб на существующее состояние, анкетирования и проведения простейших анализов и проб. Симптоматика онкологических заболеваний желудка на ранней стадии развития заболеваний проявляется слабо и, следовательно, пациент своевременно не обращается за медицинской помощью. Регистрация и анализ онкомаркеров крови в условиях массового скрининга не всегда возможно (особенно в сельской местности).
Между тем, применение существующих для решения диагностических задач в технических и биотехнических системах, теоретические исследования и практика в области систем поддержки принятия решений (СППР) и различных способов прогнозирования поведения систем [4, 14] позволяет существенным образом снизить летальность и инвалидность, уменьшить экономические затраты на лечение и последующую реабилитацию больных.
Тем самым, актуальность научных и практических изыскания в рассматриваемой предметной области биологических наук обусловливается необходимостью разработки и применения автоматизированных систем поддержки принятия решений диагностики рака желудка при скрининге и-или профилактических осмотрах на основе достижений искусственного интеллекта и информационно-компьютерных технологий.
В настоящее время, превентивная диагностика онкологических заболеваний на ранней стадии базируется в основном на применении определенных онкомаркеров (обладающих диагностической чувствительностью не более 0,7) и узкоспециализированного осмотра с учетом анализа косвенных признаков, выявленных в процессе беседы с обследуемым.
Учитывая достижения в представлении организма как целостной интегральной системы [29, 32], превентивной медицины и медицинских информационных технологий [16, 18, 23], предлагается использовать в ходе массового профилактического медицинского осмотра населения общие показатели крови. Рассматриваемый подход основывается на гипотезе об информативности крови как соединительной ткани, выполняющей транспортные функции, о функционировании различных функциональных и физиологических систем и организма в целом (особенно в случае системных нарушений, которые, безусловно, обусловливают онкологические заболевания) [20]. Применение подобных систем позволит существенным образом повысить эффективность массовых медицинских осмотров населения для выявления тяжелых заболеваний на ранней стадии и своевременно принимать решение о необходимости госпитализации или клинического обследования.
Материалы и методы
В процессе скрининг диагностики и в ходе массовой профилактической диспансеризации населения в обязательном порядке осуществляется общий анализ крови – регистрируются такие показатели как: концентрации эритроцитов, лейкоцитов, лимфоцитов, гемоглобина, цветовой показатель, СОЭ, содержание глюкозы, натрия, калия, билирубин и т.д. Эти показатели определим как частные (непосредственно регистрируемые) - множество {Х}.
Кроме того, значения показателей крови на ранних этапах развития злокачественных заболеваний организма в целом (желудка, в частности) отличаются от значений на этапах выявленного заболевания при обращении больного в клинику [27,28,21].
На основе изученного материала предлагается информационно-аналитическая модель поддержки принятия решений на этапе скрининг диагностики рака желудка, представленная на рисунке 1 [10] (аналогичный подход использовался при обработке результатов скрининг – диагностики в гастроэнтерологии [33]).
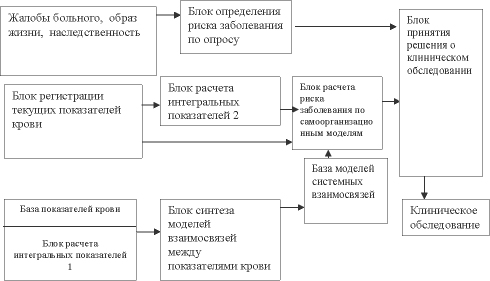
Рис. 1. Информационно-аналитическая модель скрининг диагностики рака желудка
На принятие управленческого решения о необходимости проведения клинического обследования пациента на предмет выявления рака желудка оказывают влияние различные факторы, выявленные в ходе беседы (анкетирования) с обследуемым. В «Блоке определения риска заболевания по опросу» реализуется методика вычисления значения риска соотнесения обследуемого к группе с возможным присутствием заболевания изложенная авторами в работах [1, 2].
Основной группой анализируемых показателей превентивной скрининг диагностики возможности наличия онкологических заболеваний желудка являются, согласно принятой гипотезы, значения показателей, полученных в процессе лабораторного анализа крови и онкомаркеров (РЭА, СА242, СА72.4, СА19.9). Необходимый информационный архив (клинически подтвержденный) формируется в «Базе показателей крови».
Для синтеза диагностических решающих классов формируются обучающие выборки. Процедура обучения (формирование базы знаний) реализуется в «Блоке синтеза моделей взаимосвязей между показателями крови» предлагаемой информационно-аналитической модели. В качестве исходных данных используются: множество векторов X=x1,...,xn1) и множество интегральных (латентных) показателей (вектор Y=y1,...,yn2)). Значения интегральных показателей определяется по формуле (1):
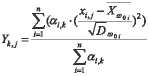 , (1)
, (1)
где: Yk,j - j-ое – значение k-го интегрального показателя, xi,j - j-ое значение i-го частного показателя крови у пациента, Xω0i - среднее значение i-го частного показателя в классе ω0, Dω0i - дисперсия i-го частного показателя крови, αi,k?[0,1] - весовые коэффициенты, определяющие информационный вклад показателя xi в формирование интегрального показателя Yk. Диагностические возможности показателей, рассчитанных по формуле (1), исследовались в работах [5, 6, 11, 34].
В предлагаемой системе предусмотрено несколько вариантов определения указанных коэффициентов: экспертное заключение, на основе дисперсионного анализа, использование информационного критерия Кульбака или критерия Стьюдента.
По сути, значения интегральных показателей характеризирует нормированное по дисперсии взвешенное расстояние «образа обследуемого» в гиперпространстве от центра альтернативного класса. Под альтернативным классом понимается класс не больных онкологическими заболеваниями людей (в дальнейшем именуемый как «здоровые») - класс ω0. Значения интегральных показателей вычисляются в «Блоке расчета интегральных показателей 1» при формировании обучающих выборок и в «Блоке расчета интегральных показателей 2» при решении диагностической задачи.
Результатом работы «Блока синтеза моделей взаимосвязей между показателями крови» является набор моделей, характеризующих множественные связи между векторами признаков X и интегральных показателей Y для основного (ω0) и альтернативного (ω1) классов. Работа «Блока синтеза моделей взаимосвязей между показателями крови» основана на использовании самоорганизационных алгоритмов структурно-параметрической идентификации метода группового учета аргументов (МГУА) [19, 24, 25,37]. Применяется ортогональный многорядный алгоритм [30], позволяющий синтезировать математические модели вида (2):
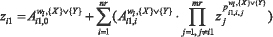 , (2)
, (2)
где: zi1 -переменная (из множеств {Х}, {Y}); Ai1,i - весовой коэффициент терма i для модели отклика функции zi1, 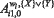 – свободный член для модели отклика zi1 в классе wl,(l=0,1) на множествах {Х} или {Y},
– свободный член для модели отклика zi1 в классе wl,(l=0,1) на множествах {Х} или {Y}, 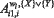 - весовой коэффициент терма i для отклика функции zi1 в классе wl,(l=0,1) на множестве {Х} или {Y},
- весовой коэффициент терма i для отклика функции zi1 в классе wl,(l=0,1) на множестве {Х} или {Y}, 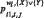 - степень аргумента j в терме i для модели отклика функции отклика zi1 в классе wl,(l=0,1) на множестве {Х} или {Y},; nr – количество рядов селекции (термов полинома); mr – количество переменных z.
- степень аргумента j в терме i для модели отклика функции отклика zi1 в классе wl,(l=0,1) на множестве {Х} или {Y},; nr – количество рядов селекции (термов полинома); mr – количество переменных z.
Для оптимизации вычислительных процедур формируется «База моделей системных взаимосвязей», в которой множество идентифицированных моделей располагается по критерию информативности.
В «Блоке расчета риска заболевания по самоорганизационным моделям» основного класса заболеваний ω1, используя вектора X и Y, по математическим моделям вида (2) вычисляются значения модифицированных векторов класса ω1 вида:
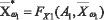 ,
,
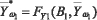 ,
,
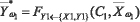 , (3)
, (3)
где А1, В1 и С1 вектора настраиваемых параметров, FX1, FY1 и FY1<{X1,Y1} - функционалы, соответствующие структурам моделей взаимосвязей исследуемых показателей (модели 2), идентифицированные соответственно на множествах {X}, {Y} класса w1.
Аналогично определяются модифицированные вектора для класса ω0:
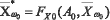 ,
,
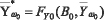 ,
,
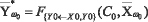 . (4)
. (4)
По полученным векторам определяются пары мер близостей D1 и D0 между векторами {X, Y}, {X1*, Y1*} и {X, Y}, {X0*, Y0*}.
Полученные значения мер близости являются аргументами для расчета риска появления исследуемого заболевания соответствующим «Блоком расчета риска заболевания по самоорганизационным моделям».
Окончательное решение о проведении клинического обследования осуществляется путем агрегации указанных показателей риска в «Блоке принятия решения о клиническом обследовании».
Выбранный математический аппарат исследования относится к классу систем распознавания образов с учителем, предполагающий использование на этапе обучения репрезентативные выборки (обучающая – для идентификации моделей и экзаменационная – для отбора наилучших моделей, наиболее удовлетворяющих субъектов диагностического процесса [12] и расчета критериев качества работы СППР).
При формировании выборок рекомендуется придерживаться соотношения «золотого сечения»: N2/N1=N1/(N1+N2), где N1 – объем обучающей выборки, N2 – объем контрольной выборки (N1≈0.62(N1+N2), N2≈0.38(N1+N2)).
Для формирования статистически репрезентативных выборок применяется следующий подход. Значения всех используемых показателей нормируются в интервал [0+е,1-е] (е=1/(N1+N2) путем линейного преобразования. Затем вычисляется для каждого вектора значений различных показателей средняя величина значений показателей. По полученным значениям осуществляется упорядочивание элементов исходного множества по возрастанию. В соответствии с выбранным соотношением N1/N2 формируются обучающие и экзаменационные выборки по следующей технологии. Все «четные» элементы входят в обучающую выборку, «нечетные» - в экзаменационную. Из полученной экзаменационной выборки в обучающую выборку переводится каждый пятый элемент.
С учетом идеологии GMDH общий процесс синтеза правил принятия решений осуществляется в соответствии со следующим методом:
1. Формируется пространство информативных признаков: X=x1,x2...,xn1 - частные показатели общего анализа крови; Y=y1,y2...,yn2 - интегральные показатели; Q=q1,q2...,qn3 характеристики образа жизни, предыдущих и существующих заболеваний, жалоб больного, наследственность и т.п.;
2. Формируются обучающая и контрольная выборки, осуществляется расчет меры доверия к исходным данным (МДД).
3. Для классов ω0 и ω1 путем применения специализированного программного обеспечения [12] формируется пакет математических моделей типа (3),(4), по которым рассчитываются коэффициенты детерминации моделей аппроксимантов Rt2 и RS2 (где t=1,...,T номер моделей (3) в общем их списке (класс ω1), s=1,...,S - номер моделей (4)) в общем их списке моделей класса ω0). Коэффициенты детерминации выступают в качестве мер доверия к адекватности математических моделей МДМ0 и МДМ1 соответствующих альтернативных классов. В пакеты моделей базы знаний СППР включаются только те, у которых значения коэффициентов детерминации превышают определенные пороговые уровни RtП и RSП.
4. Определяется общая мера доверия к адекватности по отношению к возможностям моделей описывать структуры связей между используемыми признаками для каждого по выражениям (5):
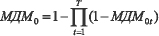 ,
,
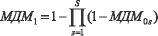 . (5)
. (5)
5. Определяется мера доверия к адекватности моделей взаимосвязи МДМ для двух альтернативных классов по формуле (6): 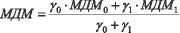 . (6)
. (6)
где: ω0, ω1 - весовые коэффициенты, определяющие предпочтение риска соотнесения пациента к классу здоровых или возможно болеющих людей.
6. Синтезируются формулы определения мер соответствия результатов текущих измерений xi и значений интегральных показателей yk с результатом расчетов по математическим моделям (3)-(4). Для расчета мер соответствия по аналогии с классическим понятием функций принадлежности введем функцию соответствия результатов модельных вычислений и измерений: fw1(di,l), fw1(dk,l). В качестве базовой переменной выступают меры близости di,l и dk,l между измеренными xi и yk и вычисленными по формулам (3) - (4) xi* и yk* значениями признаков и интегральных показателей – определяются по формулам (7):
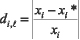 ,
, 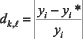 (7),
(7),
где ? - номер исследуемых классов (?=0,1).
Функции соответствия с базовыми переменными di,l и dk,l определяются в виде кусочно-линейной зависимости (8):
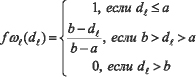 , (8)
, (8)
где dl - базовая переменная, определяемая по формулам (7).
7. Определяются уверенности UMω? в отнесении неизвестного объекта, описываемого наборами xi и показаний yk к исследуемыми классам состояний ω0 и ω1 (ω?), по моделям МГУА согласно формулы (9):
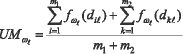 , (9)
, (9)
где ?=0,1, m1 - количество моделей, построенных по множеству Х; m2 - количество моделей, построенных по множеству Y.
С целью учета «желаемых» взаимоотношений между значениями ошибок первого и второго рода принятие классификационных решений рекомендуется осуществлять с использованием порогов Pω0 и Pω1, относительно которых строится таблица 1 принятия решений. Если значение UMω? не превышает значения порога Pω?, то элемент таблицы равен нулю. В противном случае - единице. Величины порогов Pω? определяются экспертами на этапе обучения.
Таблица 1
Диагностические заключения относительно порогов Pω? /l=0.1
|
|
|
|
|
№ ситуации |
Описание ситуации |
|
0 |
0 |
0 |
0 |
1 |
Дополнительное обследование |
|
0 |
0 |
0 |
1 |
2 |
Здоров – класс ω0 |
|
0 |
0 |
1 |
0 |
1 |
Дополнительное обследование |
|
0 |
1 |
0 |
0 |
3 |
Болен – класс ω1 |
|
1 |
0 |
0 |
0 |
1 |
Дополнительное обследование |
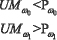
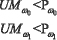
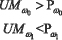
В качестве решения предлагается использовать заключения: 1 – пациент нуждается в дополнительном обследовании; 2 – вероятность присутствия рака желудка низка (пациент практически здоров); 3 – высока вероятность присутствия заболевания рака желудка.
8. Для признаков, сформированных по анализу обследуемого Q, на основании данных специальной литературы и опыта экспертов согласно рекомендациям [26, 28] определяются соответствующие риски по отношению к заболеванию раком желудка Rtω1 на основании которых формируются частные уверенности UQ в классе ω1:
UQ=FQ(Q,Rtω1) (10).
9. На экзаменационной выборке с известным, клинически подтвержденным диагнозом, проверяется качество срабатывания полученных решающих правил и, если оно удовлетворительно, то процесс обучения заканчивается. В противном случае, осуществляется корректировка параметров решающих правил в сторону минимизации ошибок классификации.
Результаты исследований
Исходное множество показателей общего анализа крови определялось экспертами – медиками в соответствии с рекомендациями [11, 25]. Была сформирована группа из 9 высококвалифицированных экспертов (четыре доктора наук, два кандидата наук и три врача высшей квалификации). Коэффициент конкардации экспертов выбранной группы составил 0,86. В результате в исходное множество анализируемых показателей были включены: Х1 – «эритроциты», Х2- «гемоглобин», Х3 – «цветовой показатель», Х4 – «лейкоциты», Х5 – «эозинофилы», Х6 –«палочкоядерные», Х7 – «сегментоядерные», Х8 – «лимфоциты», Х9 – «моноциты», Х10 – «СОЭ». На уровне значимости ошибки первого рода p<0.01 выделяем показатели Х3 (цветовой показатель) и Х9 (моноциты), которые формируют множества информативных показателей {X}. Затем, согласно рекомендациям [8,17, 31,36 ] было сформировано множество информативных показателей.
Поскольку у двух оставшихся показателей значения коэффициента Стьюдента близки, то принимается решение об объединении их в единый кластер для формирования интегрального показателя Y по формуле (1) с весовыми коэффициентами: αx3=0,44, αx9=0,56. В этом случае, согласно (1) получаем следующую формулу для вычисления интегрального показателя:
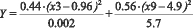 (11),
(11),
где x3, х9 – значения показателей Х3 и Х9.
Назовем этот показатель Y - «ЭрГеМо» - поскольку его аргументами являются «Цветовой показатель» и «Моноциты». Первый, в свою очередь рассчитывается, исходя из значений показателей: «Эритроциты» и «Гемоглобин».
Для его включения в множество показателей, предположительно обладающими диагностическими возможностями, убеждаемся, что ошибка первого рода различий между альтернативными классами менее 0,01.
Таким образом, множество информативных показателей включает следующие показатели крови - «Эритроциты», «Гемоглобин», «Цветовой показатель», «Моноциты», «СОЭ» и интегральный показатель «ЭрГеМо».
На основании анализа историй болезни и «добровольцев» (группа не больных раком желудка) были сформированы две выборки для каждого из альтернативных классов w0 и w1 объемами по 115 обследуемых.
Половозрастное распределение «больных раком желудка» и «не больных раком желудка» подчинялось равномерному закону распределения. Объем выборок определялся исходя из рекомендаций [15] для обеспечения чувствительности статистических критериев различий между классами на контрольных выборках на уровне 0,95. Соответственно, мера доверия к выборке МДО =0,95.
Согласно принципу «золотого сечения» обучающие выборки включали 78 объектов в каждом из классов. В таблице 2 приведены основные статистические характеристики показателей обучающих выборок в классах.
Наилучшие статистические отличия между собой показывают показатели согласно критерию Стьюдента (на уровне p<0.01): «Эритроциты», «Моноциты», «СОЭ», «ЭрГеМо». Это означает, что значения МДП ≈0,67. Поскольку, согласно таблицы 3, наблюдается пересечение классов доверительных интервалов по указанным в ней показателям, то значение меры доверия к выборкам МДВ≈0,83.
Поскольку обучающая и контрольная выборки формировались по предложенной выше методике, то мера доверия к репрезентативности МДР=1. Набор показателей определялся одновременно с анализом литературных источников справочного характера (которые можно воспринимать как экспертов) и по критерию Стьюдента - следовательно, меры доверия экспертов к выборке и к составу признаков (МДЭВ и МДЭП) принимаются за 1. В результате - мера доверия к данным МДД=0,94. Так как, контрольная и обучающая выборки взаимно репрезентативны, то МДДо=МДДк=МДД=0,94.
Значимые парные корреляционные связи в альтернативных классах показаны на рисунках 1 и 2.
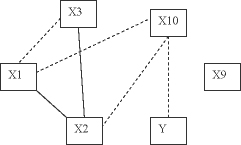
Рис. 1. Корреляционные связи в классе w0 (сплошные линии – положительная корреляция, пунктирные – отрицательная)
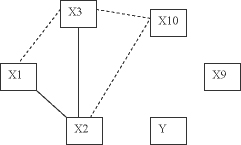
Рис. 2. Корреляционные связи в классе w1
Таблица 3
Статистические характеристики показателей для классов w0 и w1
|
Классы |
Класс w0 |
Класс w1 |
||||||
|
Показатели |
Статистические характеристики |
|||||||
|
М |
D |
As |
Ex |
M |
D |
As |
Ex |
|
|
Эритроциты |
4,24 |
0,09 |
0,47 |
0,29 |
4,1 |
0,66 |
-0,09 |
-0,176 |
|
Гемоглобин |
106,8 |
693 |
-0,55 |
-0,009 |
109 |
833 |
-0,02 |
-0,68 |
|
Цветовой показатель |
1,17 |
0,46 |
1,06 |
1,14 |
1,06 |
0,21 |
0,42 |
0,566 |
|
Моноциты |
6,39 |
10,3 |
0,77 |
0,62 |
4,1 |
4,8 |
2,08 |
9,24 |
|
СОЭ |
5,43 |
5,66 |
0,96 |
0,57 |
10,8 |
33,3 |
0,93 |
0,63 |
|
ЭрГеМо |
4,09 |
3,36 |
0,72 |
0,45 |
2,7 |
1,63 |
1,82 |
7,34 |
В таблице: M, D, As, Ex – соответственно: математическое ожидание, дисперсия, асимметрия и эксцесс соответствующих показателей.
Таблица 3
Таблица распределения результатов диагностики для класса w1
|
Обследуемые |
Результаты срабатывания правил |
Всего |
|
|
положительные |
Отрицательные |
||
|
ηω1=100·78 |
51 |
27 |
78 |
|
ηω0=100·78 |
17 |
61 |
78 |
|
Всего |
68 |
88 |
156 |
ДЧ=0,75; ДС=0,69; ДЭ=0,72.
В качестве показателей качества характеризующих статистическую достоверность диагностических правил выбраны: диагностическая чувствительность (ДЧ), диагностическая специфичность (ДС), диагностическая эффективность (ДЭ) [21, 23]. Необходимые для расчета результаты исследования, полученные на репрезентативной экзаменационной выборке обследуемых, приведены в таблице 3.
Обсуждение и заключение
Анализ корреляционных связей (рисунки 1 и 2) подтверждает структурные изменения в крови при заболевании раком желудка: исчезает корреляция между такими показателями как «СОЭ»- «Эритроциты» и «СОЭ»-«ЭрГеМо». Уменьшение количества значимых корреляционных связей позволяет предположить, что анализируемое заболевание приводит к деструктуризации процессов управления соотношений концентраций (количеств) определенных элементов в крови. Уравнения парной регрессии между этими показателями включаются в базу знаний СППР решения диагностических задач. Модели представляются следующими формулами:
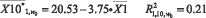 ;
;
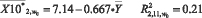 (12)
(12)
Заметим, что слабая корреляционная связь или ее отсутствие между показателями сформированного множеств {X} {Y} гиперпространства, подчеркивает их ортогональность, подтверждая полученные высокие меры доверия.
Анализ полученных моделей (приведены в [3]) , позволяет сделать следующие заключения:
- Характер линейных связей в альтернативных классах не меняется;
- У больных раком желудка людей уменьшается в среднем на 16% концентрация эритроцитов, что приводит к соответствующему изменению значения цветового показателя.
- У больных – уровень гемоглобина в крови снижается приблизительно на 16% , примерно на 20% возрастает степень влияния на него концентрации эритроцитов.
- В анализируемых альтернативных классах в моделях присутствуют как общие для них аргументы, так и оригинальные – это говорит о том, что состав крови определяется как общими для всего организма «правилами», так и специфическими для определенной системной патологии, к которой относится рак желудка;
- Количество эритроцитов в крови у не болеющих раком желудка людей характеризуется дополнительным влиянием отношением значений показателей ЭрГеМо и СОЭ, что подчеркивает возможность учета данного показателя крови для превентивной скрининг-диагностики рака желудка;
- При возникновении рака желудка снижаются диагностические возможности показателя «СОЭ» в условиях изменения связи с ЭрГеМо с отрицательно степенной на положительно степенную, что позволяет использовать этот факт в качестве диагностической характеристики;
- Количество моноцитов в крови при заболевании изменяет свою «связь» с цветовым показателем с прямой на обратную, что подчеркивает происходящие в этом случае изменения содержания «гемоглобина в эритроцитах»;
- Показатель «СОЭ» при заболевании не имеет выраженной функциональной зависимости с остальными анализируемыми показателями, что подчеркивает дестабилизации системы кроветворения;
- В функциональных зависимостях интегрального показателя ЭрГеМо на высоком уровне корреляции появляется обратная зависимость от показателя «цветовой показатель», что подчеркивает необходимость учета показателей «Эритроциты» и «Гемоглобин» при скрининг диагностики заболевания;
- В классе w1 минимизируется связь показателя ЭрГеМо с «Цветным показателем», что говорит об уменьшении роли насыщенности эритроцитов кислорода регуляции функций кроветворения при заболевании раком желудка.
Полученные компоненты базы знаний могут быть использованы как в скрининг диагностики рака желудка, так и в обучающем процессе повышения квалификационного уровня медицинских работников, например, по схеме, аналогично рассмотренной в [35] – сравниваются результаты работы диагностического модуля автоматизированной СППР (AMESDD -autonomous module expert support diagnostic decisions) и обучаемого медработника Схема учебного тестирования приведена на рисунке 3.
УЧИТЕЛЬ на основании информации о рассогласовании действий субъекта обучения с правильной оценкой ситуации (δS и δX) с помощью воздействует на субъект обучения через модуль коррекции приобретаемых знаний и навыков, оценивает уровень профессионализма, формирует статистическую отчетность. В процессе обучения осуществляется активное тестирование субъекта обучения путем генерации тестов, включающих себя: либо значения характеристик состояния виртуального пациента Х, либо его гипотетическое состояние Sit.
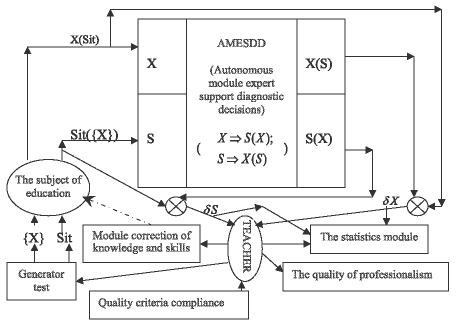
Рис. 3. Схема применения AMESDD в интерактивном тестировании профессиональных знаний и навыков, где: X – множество информативных показателей, S(X) – состояние обследуемого, соотнесенное к определенному классу и полученное по диагностическим правилам импликации X?S(X); X(S) – множество значений Х, необходимое для идентификации состояния S, согласно импликациям X?S(X); {X} – множество значений показателей Х виртуального обследуемого; Sit({X}) – состояние виртуального обследуемого согласно мнению субъекта обучения; Sit – «истинное» состояние виртуального обследуемого; δS - рассогласование между X(Sit) и X(S): δS - рассогласование между Sit({X}) и S(X); ? - блоки вычисления сигналов рассогласования
На основе полученной о состоянии виртуального обследуемого информации, собственных и приобретенных в процессе обучения знаний и опыта, субъект обучения формирует Sit({X}) или X(Sit), которые поступают на соответствующие входы AMESDD. AMESDD на основании прямых и обратных решающих правил [7] либо диагностируют состояние виртуального обследуемого (идентифицирует S(X)) либо определяет присутствие у него диагностические информативных признаков (X(S)). Блоки оценки рассогласования между правильными («эталонными») решениями (сформированными AMESDD) и предложенными обучаемыми формируют соответствующие значения сигналов рассогласования (δS и δX), по которым УЧИТЕЛЬ реализуют процедуры обучения, определенные целями программ повышения квалификации медработника.
Библиографическая ссылка
Бабков А.С., Артеменко М.В., Кирюткин М.В. ПРЕВЕНТИВНАЯ ДИАГНОСТИКА ОНКОЛОГИЧЕСКИХ ЗАБОЛЕВАНИЙ ЖЕЛУДКА ПРИ СКРИНИНГЕ С ПОМОЩЬЮ СИСТЕМЫ ПОДДЕРЖКИ ПРИНЯТИЯ КЛАССИФИКАЦИОННЫХ РЕШЕНИЙ // Научное обозрение. Биологические науки. 2017. № 2. С. 5-13;URL: https://science-biology.ru/ru/article/view?id=1049 (дата обращения: 28.07.2026).